 Теория вероятностей и математическая статистика
Простейшие статистические преобразования
Теория вероятностей и математическая статистика
Простейшие статистические преобразования
Прежде чем переходить к детальному анализу наблюденных статистических данных, обычно производят их предварительную обработку. Иногда результаты такой обработки уже сами по себе дают наглядную картину исследуемого явления, в большинстве же случаев они служат исходным материалом для получения более подробных статистических выводов.
Вариационный и статистический ряды. Часто бывает удобно пользоваться не самой выборкой X1, …, Xn, а некоторой ее модификацией, называемой вариационным рядом. Вариационный ряд X1*, …, Xn* представляет собой ту же самую выборку X1, …, Xn, но расположенную в порядке возрастания элементов: X1* ≤ X2* ≤ … ≤ Xn*. Такое преобразование не приводит к потере информации относительно теоретической функции распределения F(x), поскольку, переставив элементы вариационного ряда X1*, …, Xn* в случайном порядке, мы получим новый набор случайных величин X′1, …, X′n совместная функция распределения FX′1,…,X′n(x1, …, xn) которых в точности совпадает с функцией распределения FX1,…,Xn(x1, …, xn) первоначальной выборки X1, …, Xn.
Если среди элементов выборки X1, …, Xn (а значит, и среди элементов вариационного ряда X1*, …, Xn*) имеются одинаковые, то наряду с вариационным рядом используют представление выборки в виде статистического ряда (табл. 2), в котором Z1, …, Zm представляют собой расположенные в порядке возрастания различные значения элементов выборки X1, …, Xn, a n1, …, nm — числа элементов выборки, значения которых равны соответственно Z1, …, Zm.

Статистики. Статистикой S=(S1, …, Sk) называется произвольная k-мерная функция от выборки X1, …, Xn:
S1 = S1(X1, …, Xn),
…
Sk = Sk(X1, …, Xn).
Как функция от случайного вектора (X1, …, Xn) статистика S также будет случайным вектором, и ее функция распределения
FS1,…,Sk(x1, …, xk) = P{S1 < x1, …, Sk < xk}
определяется для дискретной наблюдаемой случайной величины X формулой
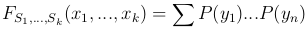
и для непрерывной — формулой
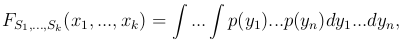
где суммирование и интегрирование производится по всем возможным значениям y1, …, yn, для которых выполнена система неравенств S1(y1, …, yn) < x1, …, Sk(y1, …, yn) < xk.
Статистика S называется достаточной, если она содержит всю ту информацию относительно теоретической функции распределения F(x), что и исходная выборка X1, …, Xn. В частности, вариационный ряд всегда представляет собой достаточную статистику.
Эмпирическая функция распределения. Эмпирической функцией распределения называют функцию F*(x), определяющую для каждого значения x относительную частоту события X < x:
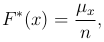
где μx — число элементов выборки, значения которых Xi меньше x.
Построение эмпирической функции распределения F*(x) удобно производить с помощью вариационного ряда X1*, …, Xn*.
Гистограмма, полигон. Для наглядности выборку иногда преобразуют следующим образом. Всю ось абсцисс делят на интервалы (xi, xi+1) длиной hi=xi+1-xi и определяют функцию p*(x), постоянную на i-том интервале и принимающую на этом интервале значение p*(x)=νi/(nhi), где νi — число элементов выборки, попавших в интервал. Функция p*(x) называется гистограммой.
При наблюдении дискретной случайной величины вместо гистограммы используют полигон частот. Для этого по оси абсцисс откладывают всевозможные значения b1, …, bL наблюдаемой величины X, а по оси ординат, пользуясь статистическим рядом, либо числа ν1, …, νL элементов выборки, принявших значения b1, …, bL (полигон частот), либо соответствующие наблюденные частоты p1*=ν1/n, …, pL*=νL/n (полигон относительных частот). Для большей наглядности соседние точки соединяют отрезками прямой.
Выборочные характеристики. Эмпирическая функция распределения F*(x), построенная по фиксированной выборке X1, …, Xn, обладает всеми свойствами обычной функции распределения (дискретной случайной величин). В частности по ней можно найти математическое ожидание (выборочное среднее):
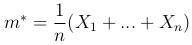
второй момент (выборочный второй момент)
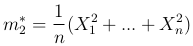
дисперсию (выборочная дисперсия)
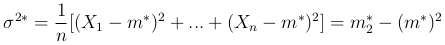
и т.д.